Intro
P4, 即 Portable Parallel Processing Pipelines,是由 Jianping Kelven Li、Kwan-Liu Ma 发表在 TVCG 2020 的工作。其提出了一个结合了声明式设计标准和 GPU 计算的、用于构建高性能可视化系统的信息可视化框架,利用 GPU 计算来加速数据处理过程和交互可视化应用中的可视化渲染流程。其提供的 API 可以用于数据转换、视觉编码、交互的快速开发。P4 通过在保持对设计标准的高度灵活性和可自定义性的前提下,简化了经 GPU 加速的可视化系统的开发流程。同时,相对于其他工具链,P4 在创建可交互的可视化方面提供了极大的效率提升。
动机
具备交互的可视化系统,尤其是在处理大规模数据时,需要在数据处理和可视化渲染两个任务上具备高效性。而主流的计算设备大多可以通过 GPU 为这两个任务提供性能提升。因此本文尝试探索 GPU 计算在这两个任务上的潜力,以为开发人员提供一个新的、高性能的可视化开发工具。
P4 主要针对 4 个目标进行设计:
- Performance:旨在合理分配利用 GPU 资源来储存、处理数据,以获得无缝的高性能
- Productivity:旨在提供一个良好架构的、声明式的 API
- Programmability:旨在提供高度的可定制性和灵活性,让用户可以自定义数据操作与视觉编码的复杂逻辑
- Portablity:P4 作为利用 WebGL 的 Web 开发框架,可在不同的现代浏览器中按预期工作
相关工作
可视化工具链
许多可视化工具与库均提供声明式的语法来设计可视化应用,包括 ggplot2、Protovis、D3、Vega、Vega-Lite 等。声明式的语法可以将可视化、互动的具体设计从其背后的执行细节解耦出来,让开发者更聚焦在和应用相关的设计决策上。但现有工具极少利用到 GPU,难以保证大数据的实时互动性。
在与 GPU 相关的技术与可视化工具的结合发面,包括 OpenGL、WebGL 等图形 API,General Purpose GPU 的若干 API OpenCL、CUDA等,以及可视化社区一些使用 shader 来绘制可视化结果的尝试。不过目前的工作大多聚焦在使用 GPU 来渲染可视化结果,而没有利用到其并行的特性来处理数据。
高性能可视化方法
为了应对大数据的可视化需求,目前已有若干方法来改善系统性能。包括使用过滤、数据降采样、数据方块的数据规约方法等。部分诸如 Tableau、Spotfire 等商业产品也使用分布式系统与运计算来预先处理大数据。这些方法需要对数据的先验知识,也会有额外的网络开销。
另一种方式为隐藏延迟来提升交互系统的体验,例如多线程的并行处理、数据的内存缓存、增量可视化等方式。也有若干工作利用到 GPU 渲染来提升性能,包括使用 GPU shader 渲染航班轨迹、预先将多维数据计算成 GPU 纹理的处理方式、使用 GPU 操作来实现常用的数据库操作符等工作。
设计与 API
概览
System Model:架构上,P4 的系统模型主要由 4 个部分组成:
- 一个用于将 JSON 文档转换成 JS 函数调用的翻译器
- 一个用于调用 JS 函数的 API
- 一个用于在运行时将用户指定的参数转换成 GPU 程序的生成器
- 一个用于管理输入与输出的控制器
Data Model:数据模型上,P4 使用以列为主要顺序(Column Major Order,即同一维度的数据在内存中相邻)的统一数据模型来编码在 GPU 内存中的多维数据。该数据模型同时支持 numerical 和 categorical 两种数据类型,以单精度浮点数作为数据格式。GPU 内存同时存储了元数据。
Execution Model:运行模型上,P4 指定包含数据模式和一系列用于数据转换(Data Transformation)和可视化的操作符的 pipeline 为核心流程。运行时,这些操作符被转换成 GPU 程序。在一个 pipeline 内,所有数据和程序均在 GPU 上完成,没有 CPU 和 GPU 之间的传输消耗。
API
P4 的声明式语法使用类似 JSONiq 和 NoSQL 数据库的设计。数据转换相关的运算符有:
Derive:从已有值生成新的值供后续运算Match:筛选数据,使得满足条件的数据保留下来Aggregate:使用指定的聚合函数来分组数据
这些运算符可以以任意顺序组合。和可视化映射相关的属性有:color, opacity, width, height, x, y,支持 circle, line, rectangle 三种标记符号。其中 x 和 y 均可以指定为数组,渲染结果会是一个平行坐标图。
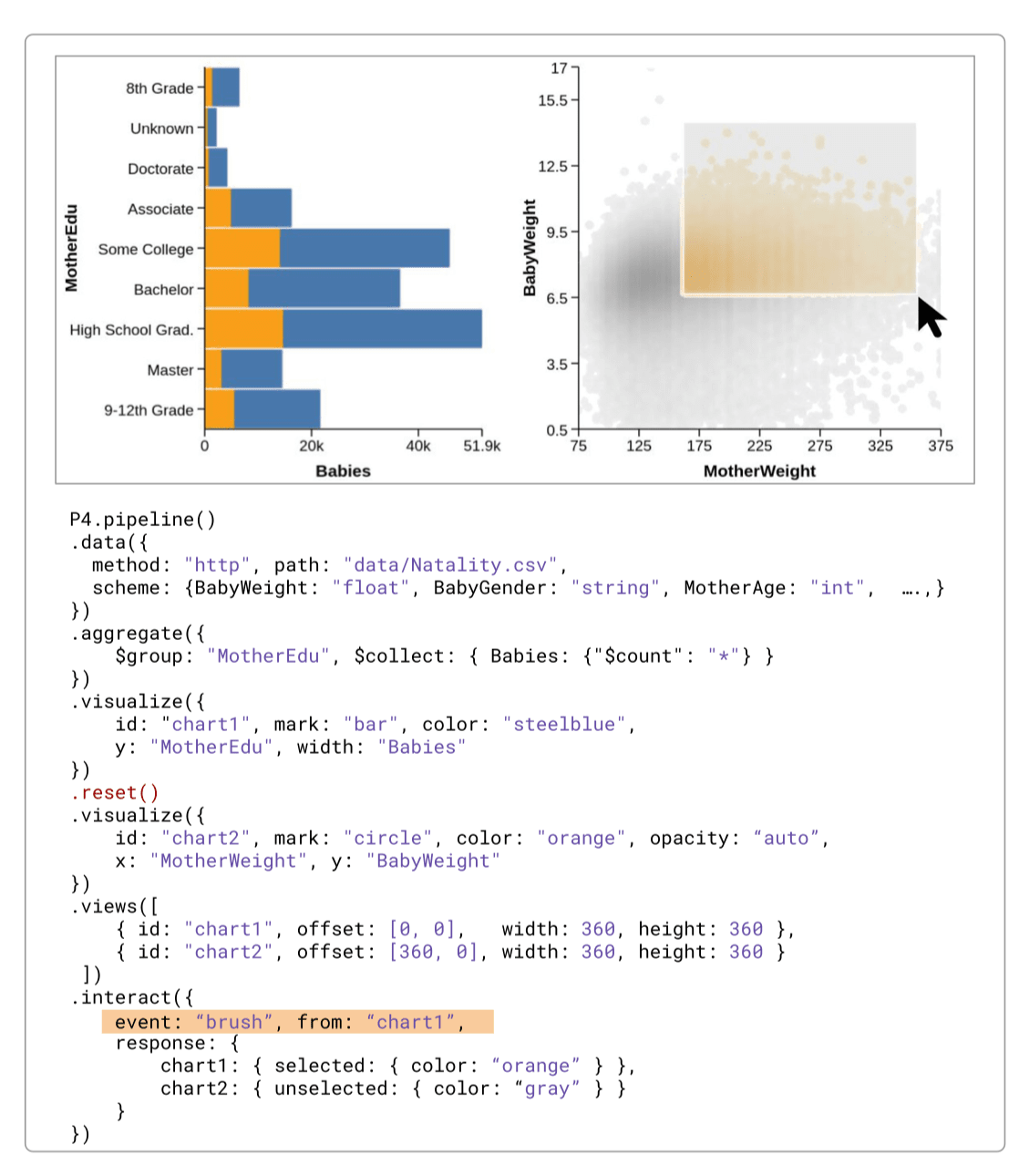
交互方面,P4 设计了高层的交互式语法。一个交互包含 event 和 response,其中 event 可以为 click, hover, brush, zoom, pan,response 则指定了 pipeline 中的每个可视化图表是如何根据 event 来重绘视图的。当 event 触发时,与其关联的数据值、参数等信息会被选中,用于在 response 中指定选中部分和未选中部分分别是如何表现的。
具体地,一个包含数据转换和可视化操作的例子如下:
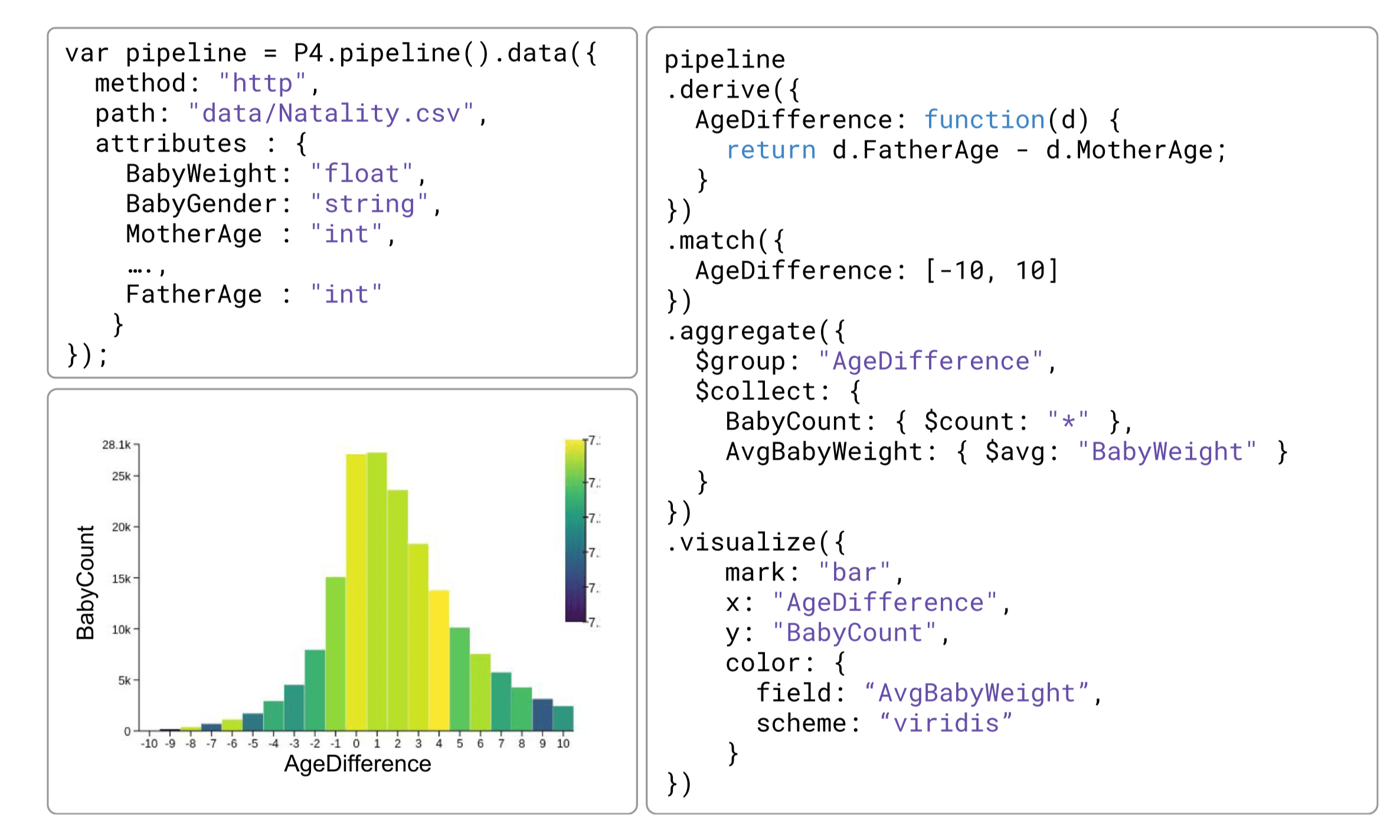
在此基础上,P4 提供了控制流相关的运算符,包括:
register,用于在 GPU 中保存pipeline的状态、缓存中间结果resume,用于将新的数据输入和设置输入到先前缓存的中间结果中reset,重置当前的状态来使用原始的数据来计算新的可视化结果export,以 JS 数组或 JSON 格式导出数据结果
一个包含交互和控制流的的例子如下:
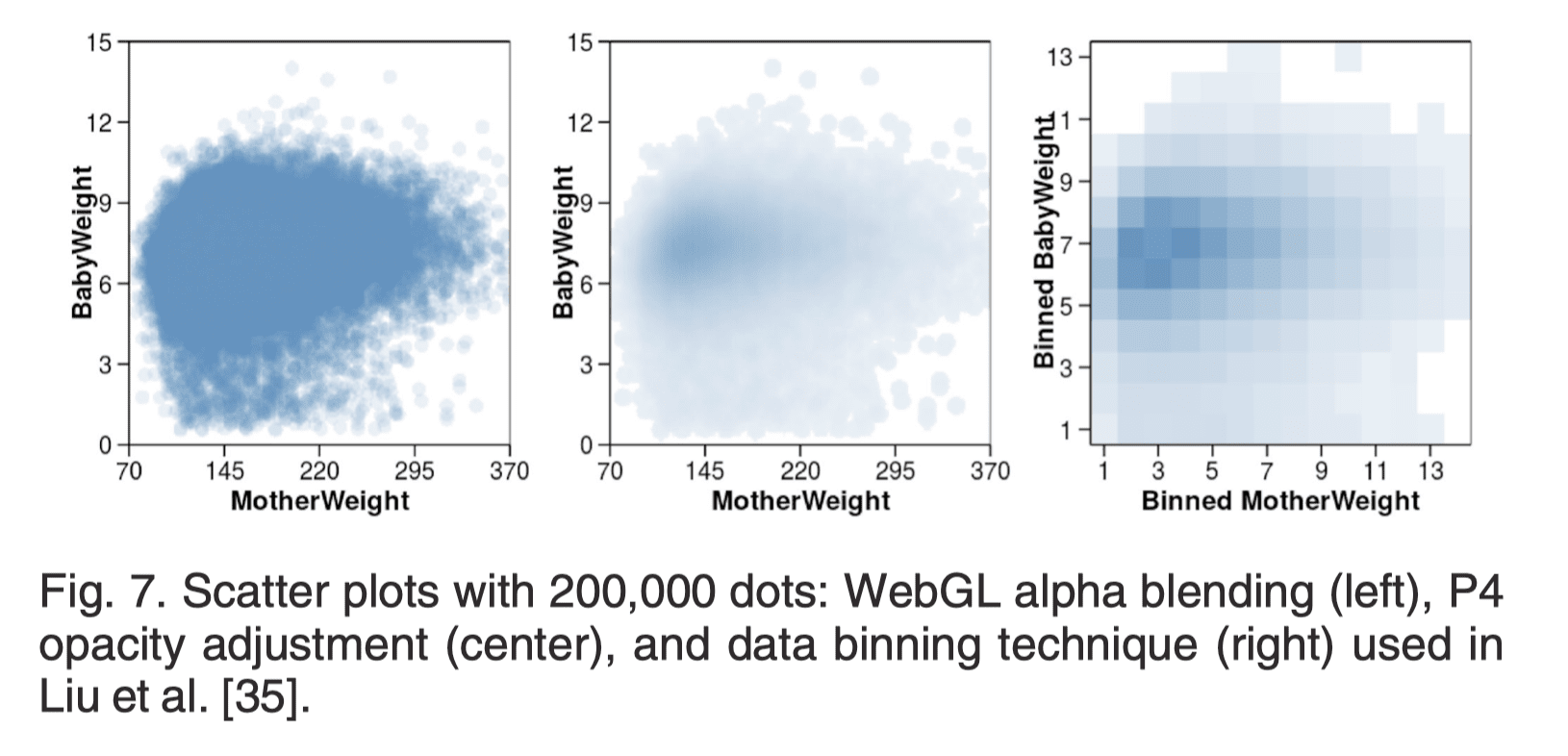
为了避免大量数据渲染结果下的视觉混乱杂乱,P4 参考 Z. Liu 的感知增强算法,将数据值映射到透明度和颜色。具体地,在 GPU 中并行计算所有像素归一化的数据密度,然后基于下列计算方式更改像素的颜色与透明度:
其中 为视图中视觉符号重叠的最大数量, 为当前像素的视觉符号数量。经实验, 默认为 , 为 时,可取得最佳观感。
实现
并行原语 Data-Parallel Primitives
在 P4 的实现中,为了使得数据转换和可视化过程可以并行,工程上采用了基于函数编程的原语(包括 map、 filter、reduce)。具体地,包括以下原语:
Fetch:计算数据在 GPU 中的内存地址,并返回数据用于后续计算Map:将现有数据根据用户指定的逻辑映射到新的数据,常用于计算中间值Filter:根据具体条件来选择一部分数据的子集。不满足条件的数据将不会被 Fetch,以避免取得后又丢弃数据所造成的带宽浪费Reduce:使用例如 count、sum、avegrage 等统计方法并行地将一系列数据规约到单个值的输出
在实际情况中,所有的 GPU 程序均是在运行时基于上述并行原语来生成的。P4 先根据 pipeline 的工作流程和执行模式来生成若干原语。(todo)
高层次的运算符,如下所示,可以通过结合这四个并行原语来得到。
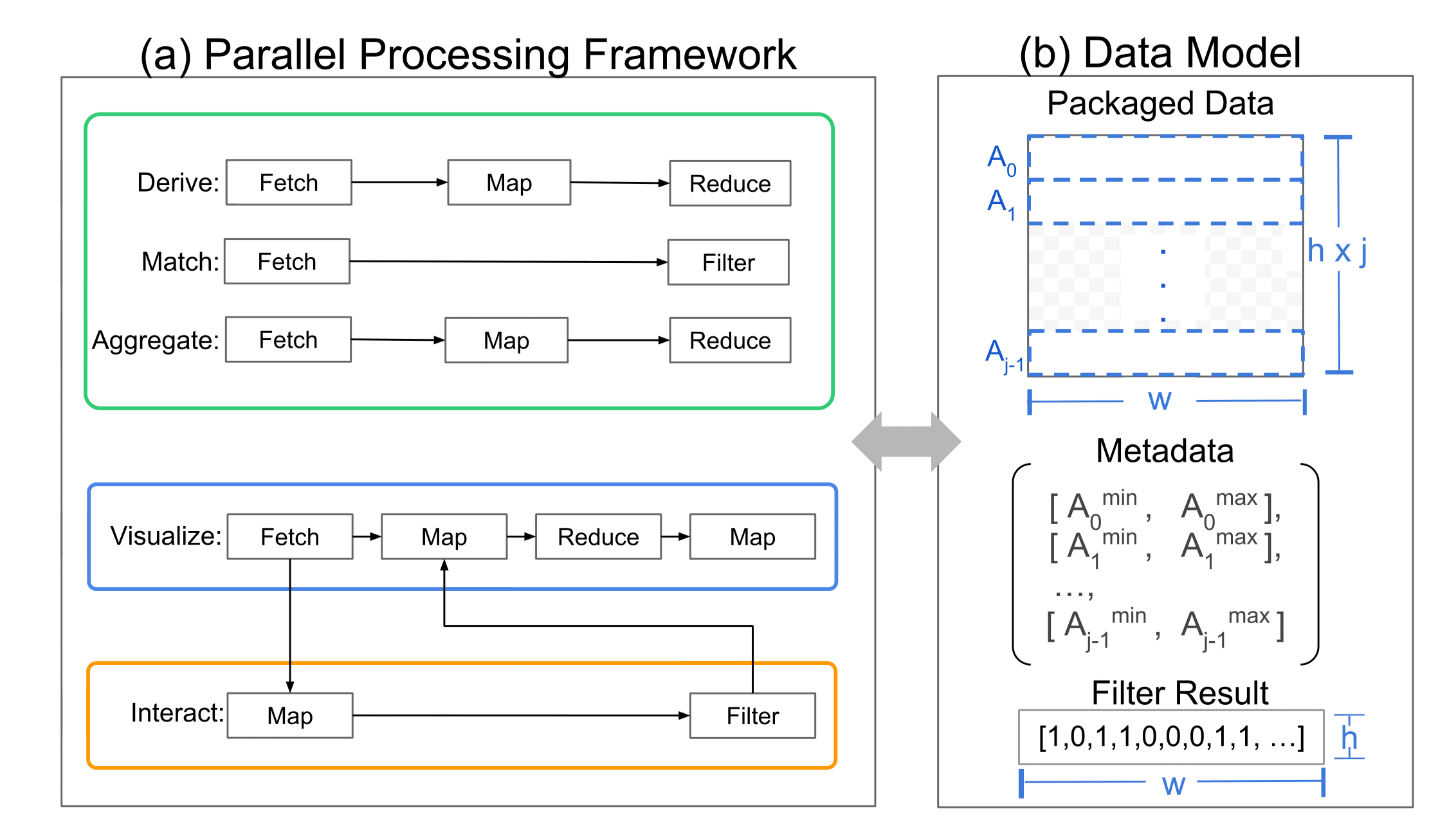
Derive:通过Fetch获取已有数据,再使用Map来映射出新的值,最后的Reduce用于计算新的数据的元数据(包括最小值、最大值等)Match:通过Fetch获取已有数据,再使用Filter筛选数据Aggregate:通过Fetch获取单组或多组数据,对每组数据根据不同的聚合操作执行Map,最后通过Reduce来获取元数据Visualization:该运算将数据映射到视觉编码中。使用Fetch获取数据,使用Map来映射出这些数据对应的位置、颜色等其他视觉元素所需要的信息。Reduce执行出来的最大密度与最小密度将用于视觉感知增强,而最后的Map用于计算每个像素具体的输出值。Interact:如前文所述,Interact使用 event-response 对来根据用户选择来改变视觉编码。在原语的使用上,其在Visualization的基础上,增加一个额外的Map和Filter。Map用于获取用户交互在数据维度上的选择范围,Filter用于基于这些范围来改变对应视觉元素的视觉编码。
数据管理实现
P4 利用基于 WebGL 1.0 的 API,使用统一的数据模型来管理数据。所有的多维数据均按照数据项的顺序,以列数组的形式存储在二维纹理中。纹理使用单精度浮点数,最大宽度和高度为 8192。对于大小大于 的数据,P4 将会将其分割为多个纹理。各个数据项的元数据以 WebGL Uniform Buffer 存储,数据转换操作的结果将会被写入离屏帧缓冲区,供后续操作使用。P4 管理了输入和输出纹理的指针地址,以保证数据流向的正确性。
可视渲染实现
渲染上,P4 使用 WebGL 在 Canvas 上绘制视觉元素,用 SVG 元素渲染简单的坐标信息。系统内存中保存有元数据的副本,供 SVG 渲染使用。对于数据为整型的类别数据,GPU 与系统内存中的元数据也存有所有各个类别属性的引用。
另外,出于 WebGL 对跨 Canvas 数据共享的限制,为了共享数据源,多个视图将被渲染在同一个 Canvas 中的不同区域。对开发者而言,另一种方式是使用多个 P4 pipeline 来分别渲染。
GPU Shader
P4 利用 WebGL 的着色器来实现自己的四个并行原语。具体地:
Fetch:利用 WebGL 处理纹理的高效机制来直接方位纹理Map:利用顶点着色器来计算中间结果,再利用片段着色器来将映射结果输出到对应位置Filter:使用顶点着色器来检查某数据是否符合过滤条件,满足条件的数据由片段着色器输出Reduce:利用 Blending 对 framebuffer 中的数据进行 count、sum、max、min 等聚合操作,使用两次 pass 可以获得 average 和 variance
例如,聚合操作(包括 Fetch, Map, Reduce)的 GPU 代码生成过程如下:
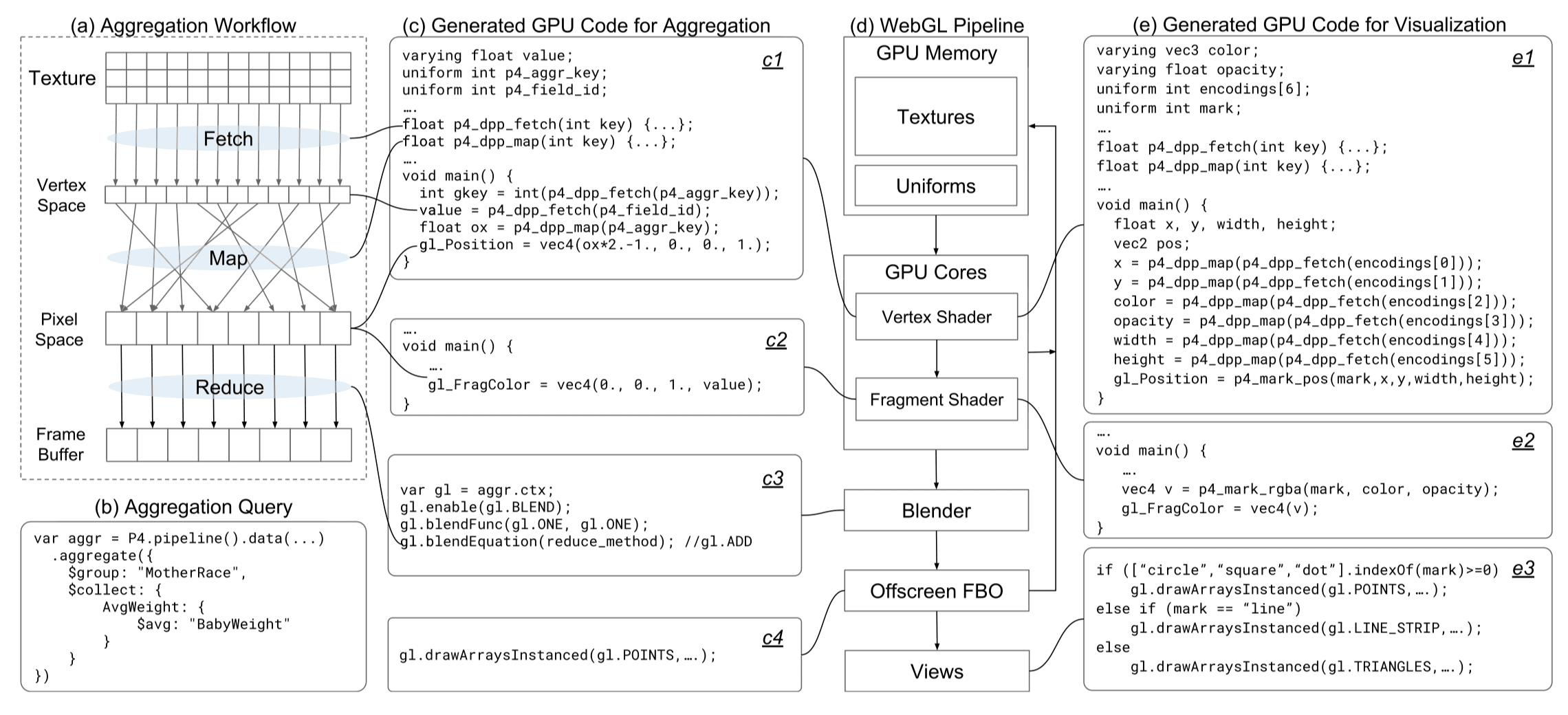
由 P4 生成的 GPU 程序和 pipeline 的流程相对应,这些 GPU 程序在 WebGL 管线内的运行如 e 所示。顶点着色器使用 Map 来获取归一化的数据值、计算视觉元素的位置,片段着色器来输出颜色、透明度、形状等其他视觉编码,最终根据不同的视觉元素调用对应的 WebGL 绘制调用(e3)。
并行原语也可以用于运行时的代码生成。例如对于一个类型数据的 Derive 的运行时代码生成如下图所示,用户指令中的逻辑被以并行数据原语的形式嵌入到了顶点着色器程序中。

评测
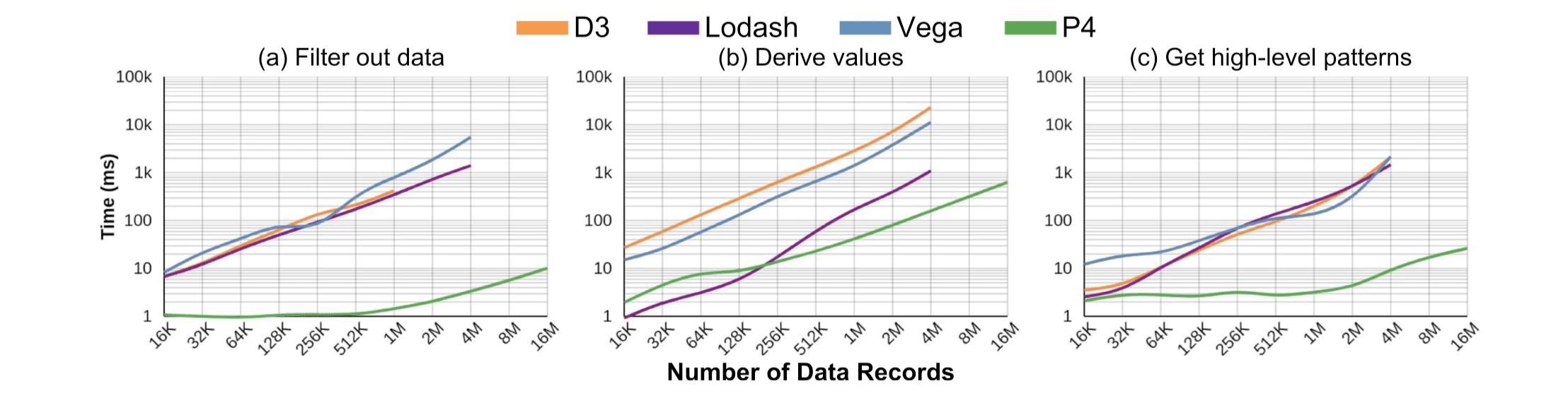
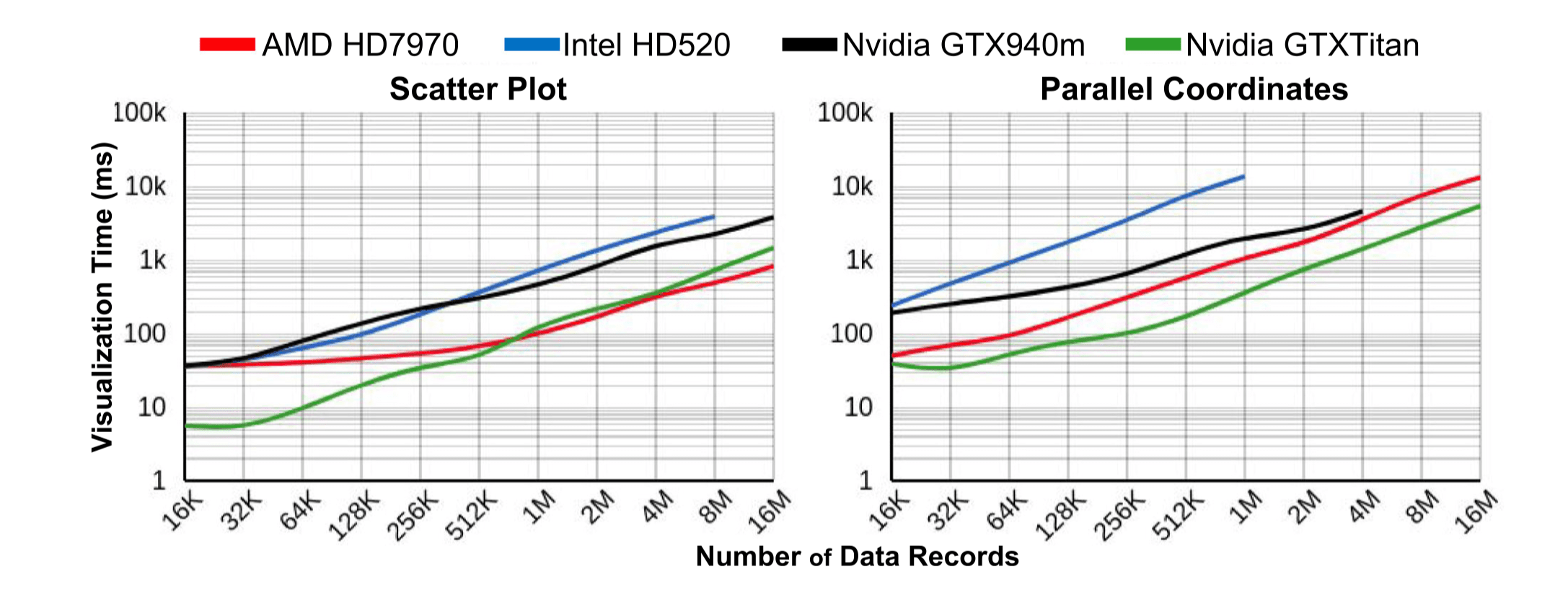
以下测试使用 Chrome 浏览器,数据范围从 16K 到 16M 不等,在 32G i7-4790 机器上重复运行 10 次。为了消除 CPU 到 GPU 之间的数据传输时间以评测真实的 GPU 程序运行效率,在每次渲染完成后都随机读取了一个像素的值,来确定渲染结果已经完成写入。不同库的数据转换性能对比:
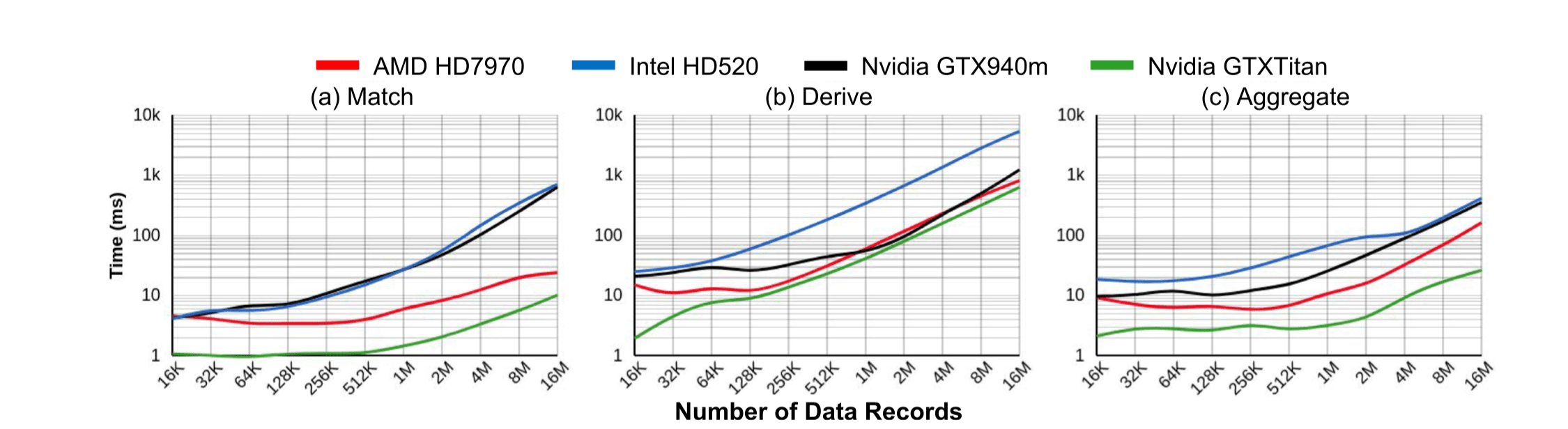
不同等级 GPU 下三种数据转换运算性能对比:
不同库的平均初始化时间及首帧渲染时间对比:
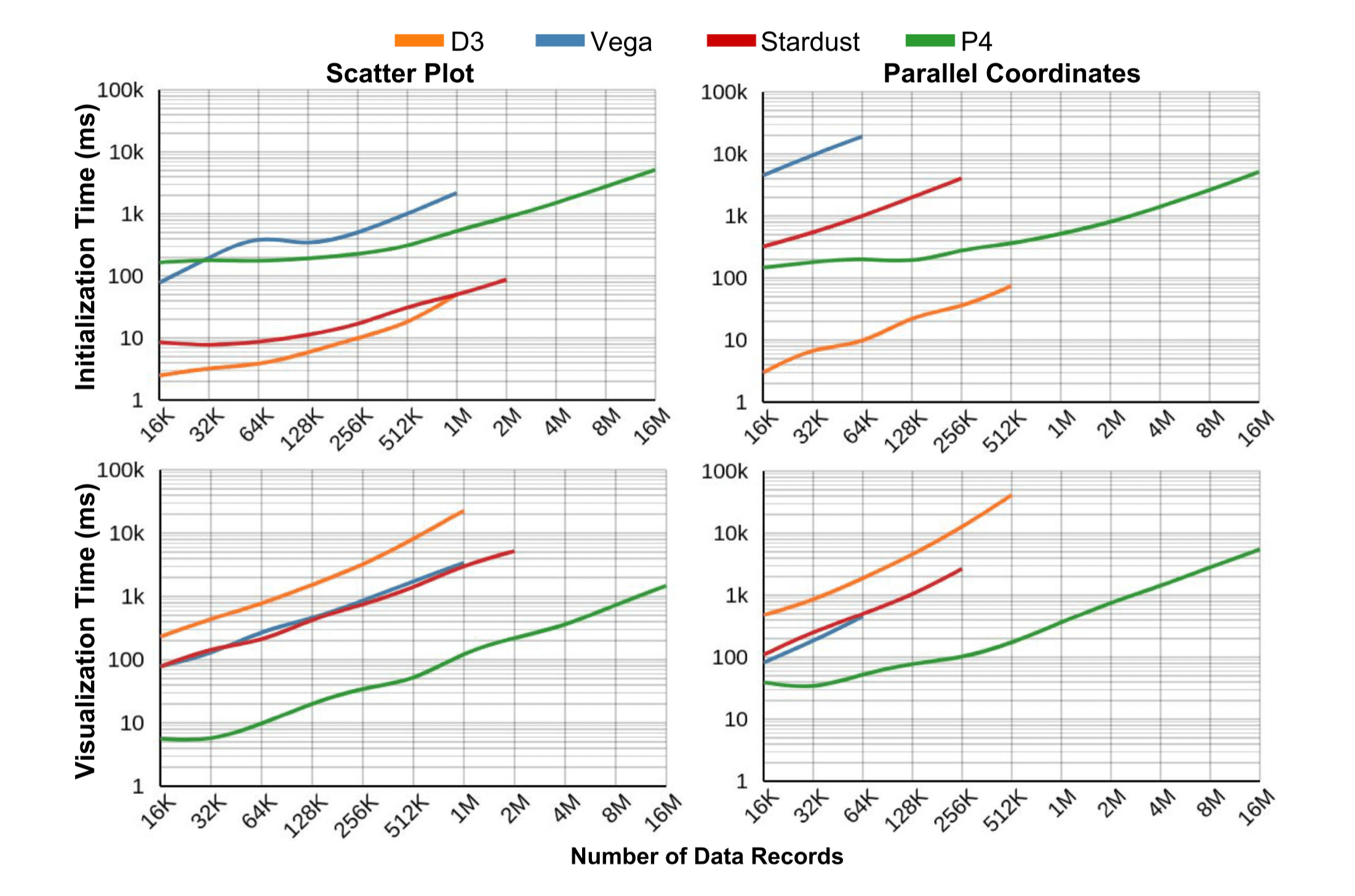
不同等级 GPU 下不同类型图的首帧渲染时间对比:
案例
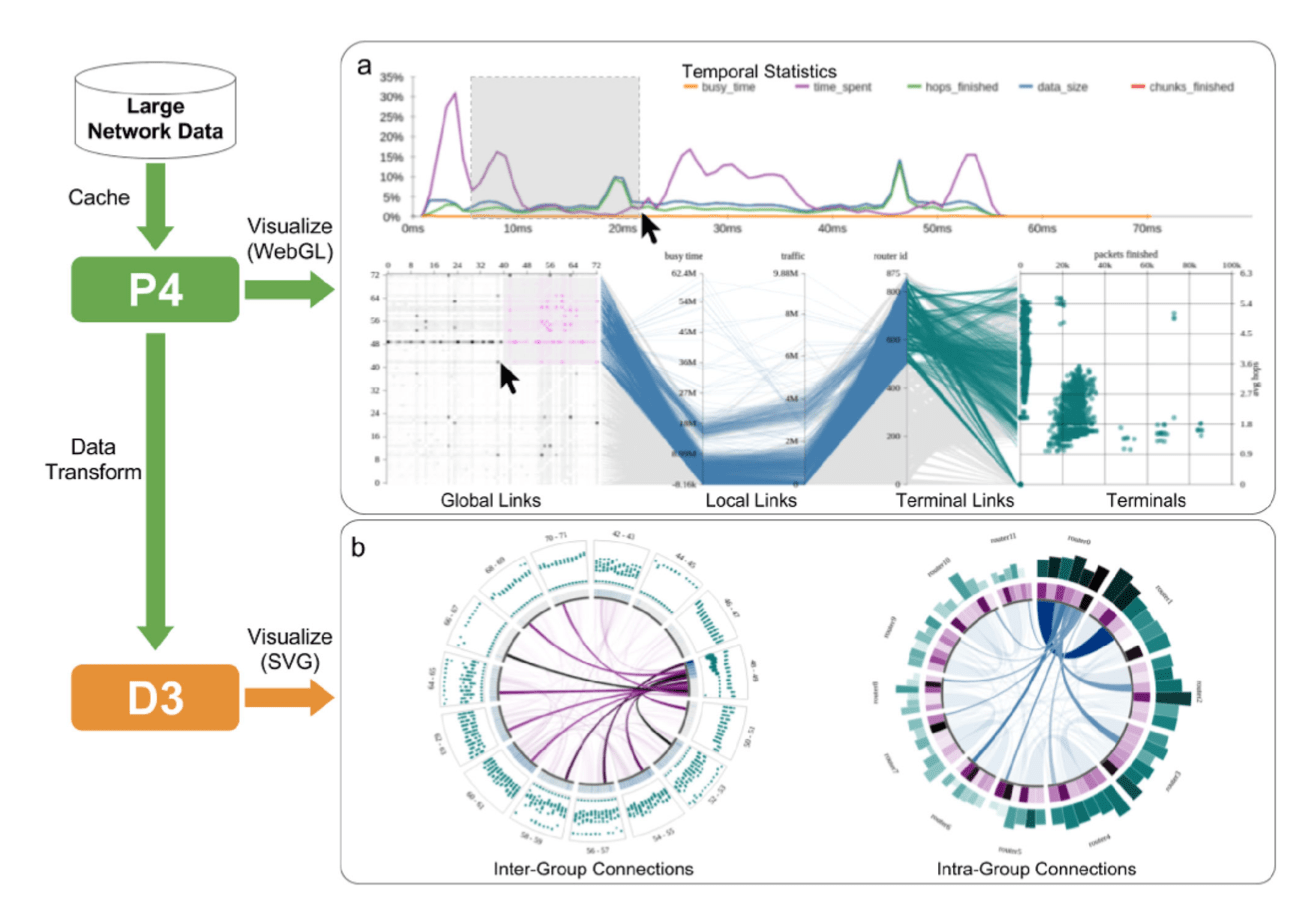
超算网络
超算网络集群中,节点间网络的连接性对性能有较大的决定作用。如图为利用 P4 开发系统,用于探索超级计算机的行为来优化性能。系统结合了 P4 和 D3,使用 P4 来显示全局连接、本地连接、终端连接和终端等连接的延迟信息,使用 D3 来对 P4 转换出来的数据绘制相对小规模的可视化视图。从 GPU 到 CPU 传输大数据导致的开销较大,并在结合其他工具开发可视化时,设计者和开发者应当考虑到这一点以提升实时互动性。
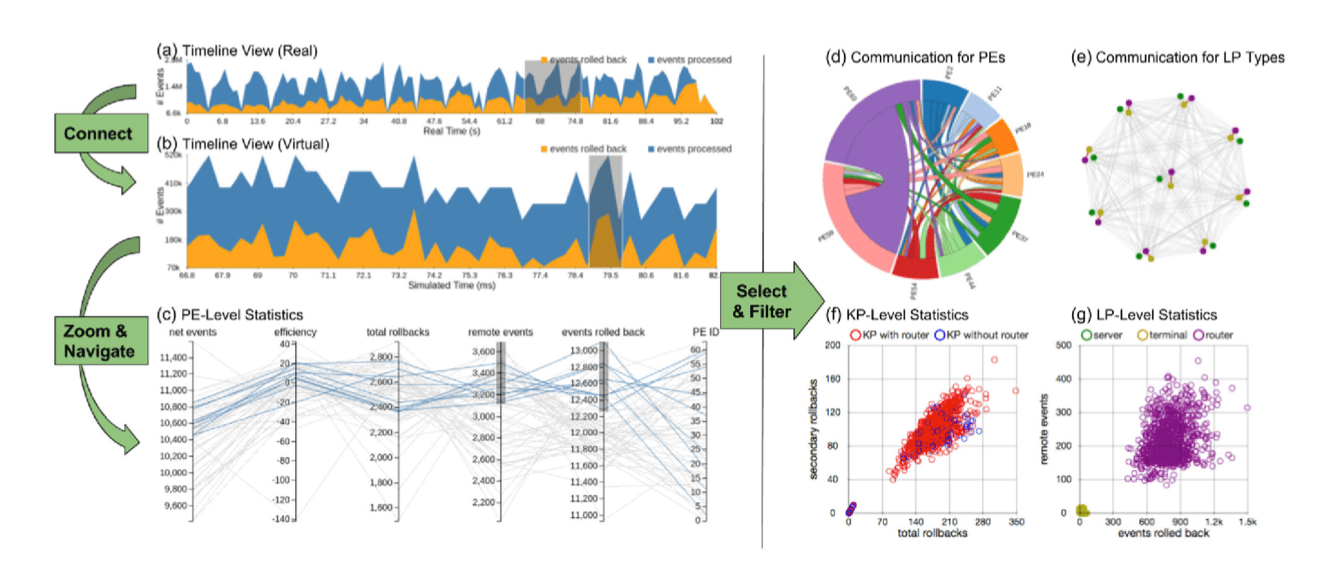
PDES (Parallel Discrete-event Simulations)
PDES 即并行离散事件仿真,让研究人员可以建模、学习复杂的物理现象。与 PDES 研究者合作,P4 团队改进了一个用于评估和改进大规模 PDES 系统的高效性与可伸缩性的可视分析系统的互动性。系统中,先前的数据处理大多基于 CPU 计算,产生了较大延迟。现在,通过将数据处理和可视渲染及交互处理均移动到 GPU 计算,大大改进了系统的性能,提升了时序上的分辨率。
P4 Player
一个简单的 Web 应用,对接 HTML5 的 API,允许用户自由的上传硬盘中的 JSON 数据,并实时编写、运行、测试 P4 程序,探索数据集内容和 P4 的可视化结果。
讨论
性能与可表达性
低层次的可视化语法(细粒度的控制)和高层次的可视化语法(简介的表达方式)之间存在 expressiveness 与 performance 的 trade off。相比于 P4,D3 继承了 DOM 节点的可表达性,而 Vega 与 Vega-Lite 通过利用 JavaScript 的灵活性为数据转换和可视化提供了更多可能性。但在性能上,这样的做法和 JS 单线程的特性也限制了他们的表现。P4 希望能够达到和 Vega 相同的可表达性,并严格分离数据转换、可视映射和交互设计的几个模块,来确保各个运算符都是可以并行加速的。P4 既通过声明式语法继承了 DOM 节点和 JS 的可表达性,也充分利用 GPU 计算来并行、多线程地处理工作,从而提高了性能。
优化与拓展
目前,P4 的开发基于 WebGL 1.0 API,这使其具备良好的兼容性。但 WebGL 2.0 即将发布(论文发表时),提供了更多针对现代 GPU 相关的优化,具备进一步优化 P4 性能的可能性。当前由于 Blending 操作的限制,Reduce 只支持 min、max、avg 等少量聚合操作,而在未来,计算着色器(Compute Shaders)或可编程 Blending 的引入可能会使得 P4 突破这个限制。
未来,P4 也具备应用到标准桌面环境中的可能性,而不仅局限于 Web 运行时,使用相同的架构即可。数据并行原语的思想,也基于了 P4 充分的可拓展性,新的操作符可以通过组合现有并行原语或引入新的原语来得到。
后续工作
- P4 高度依赖 GPU 的性能和内存,数据大小超过 GPU 内存时,未来可能会引入渐进式的可视分析方法(事实上在后续发表的 P5 中,P4 团队也完成了这一工作),通过数据分块、预处理等方式实现
- P4 作为高层次的语法,表达性仍有进一步提升的空间,以支持数据转换和可视化过程中更高的自定义性
- P4 目前的可视化基于笛卡尔坐标系和少量几种视觉符号,未来可以探索更多潜在的可视化样式(如树图等)
[1] J. K. Li and K.-L. Ma, “P4: Portable Parallel Processing Pipelines for Interactive Information Visualization,” IEEE Transactions on Visualization and Computer Graphics, vol. 26, no. 3, pp. 1548–1561, Mar. 2020, doi: 10.1109/TVCG.2018.2871139.
[2] Z. Liu, B. Jiang, and J. Heer, “immens: Real-time visual querying of big data,” Comput. Graph. Forum, vol. 32, no. 3pt4, pp. 421–430, 2013.
[3]“The Book of Shaders.” https://thebookofshaders.com/ (accessed Apr. 26, 2022).
[4]“jpkli/p4: P4: Portable Parallel Processing Pipeline,” GitHub. https://github.com/jpkli/p4 (accessed Apr. 26, 2022).