Intro
Hashedcubes 是 Cicero A. L. Pahins 等作者发表在 TVCG 2017 年上的工作,旨在提出一个可以对大数据进行实时可视探索的数据结构。该数据结构可以满足低内存占用、低查询延迟、简单易实现等要求。经实验,在部分情况下,Hashedcubes 可以在空间占用上比最新的方式减少两个数量级的占用。本文描述了 Hashedcubes 的数据结构与构建方式,以及其在注入聚类散点图、直方图、热力图等可视化图表中的应用方式。也用真实世界中的若干数据集进行了评测,从内存占用、构建时间、查询延迟等维度来进行评价。
动机
高维大规模数据的实时可视化系统开发中时常需要解决数据查询的高延迟问题。对数据简单的线性扫描往往会使得延迟不可接受,而近年来提出的种种复杂数据结构虽然能带来高效的查询效率,却由于复杂的实现和 GPU 的支持而难以和现有的系统有机整合。于是本文提出思考:是否存在一个相对简单的数据结构,既能够提供和复杂数据结构想当的性能表现,又能够保持较低的内存占用与实现的简洁性?
主要工作
于是本文主要做的工作包括:
- 提出了 Hashedcubes,一个用于对高维大规模数据的实时可视化探索的简洁数据结构
- 一个对 Hashedcubes 的实验性的、验证性的系统实现,用于评测内存占用与查询、构建时间
- 一系列关于使用 Hashedcubes 的 trade-off 讨论
与本文相关的工作包括大规模数据的可视化分析、时空数据分析与相关系统实现的若干挑战等。
Hashedcubes 的构建
直观认知
文章讲述了设计 Hashedcubes 背后的动机与逻辑。可视化图表中常见的图表绘制问题背后的数据来源往往是「计数」(如某一天、某一区域发生的事件次数作为视觉编码中的一个符号)。此外,数组的长度不受其内元素顺序的影响。因此,对于数组 中一个连续区域的元素集 ,我们可以使用一对索引 来表示,称为 pivot。通过将 划分为互不重合的区域,我们可以通过若干 pivot 来表示整个数组。这样的一种表示方式允许用户在查询时快速跳跃数据,也充分保留了划分的自由性。而每一个划分又可以作为一个新的数组,允许后续在此划分上做进一步划分。
直观上,这种层级的划分机制便是 Hashedcubes 的基础。例如,对于一个具有星期数 ,小时数 ,网络端口 三个维度的网络日志数据集,我们可以依次对每个维度进行划分并得到一系列的 pivot 数组,即三个,分别对应于 维度、 维度、 维度。有了这些 pivot 数组之后,计数统计也就可以快速完成,而无需依次扫描数组了。在次基础之上,再给每个 pivot 记录他们所下属的更细维度的范围(如 维度的 pivot 同时也会记录这个 pivot 所下属的 维度的范围),便可以在不同层级的 pivot 数组间建立联系 —— 这些机制是对 Hashcudes 的直观认知。
构建流程
Hashedcubes 的构建需要按照一定的维度顺序。其支持的维度类型包括:空间(spatial)、类别数据(categorical)、时序(temporal)。Pivot 层级的构建技术上支持任意顺序,但在实际中往往采样采用空间 -> 类别 -> 时序的顺序。多层的 pivot 数组本质上表达了树状的层级结构,每个节点包含的索引起止信息允许聚合操作能够从中快速获取大小信息。
下图为 Hashedcubes 针对一个简单包含 10 个点的时空数据的构建流程示例。其维度为:[[Latitude, Longitude], [Divice], [Time]]。分别每个维度进行聚合、排序,可以得到如右上侧的排序结果;针对每一维度生成的 pivot 数组也如图所示。Hashedcubes 最终保留的结果便为排序后的数组与一系列的 pivot 数组。
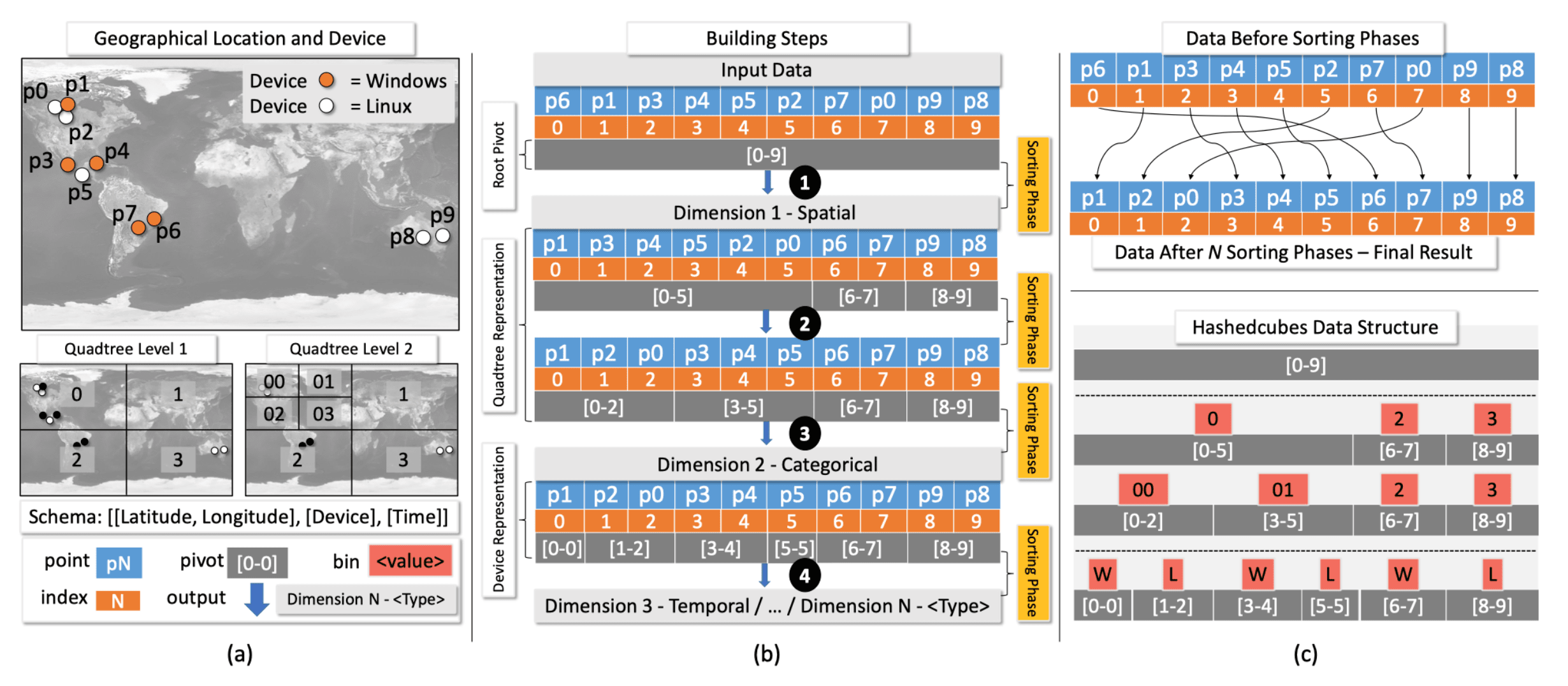
和 Nanocubes 相比,Hashcubes 的没有提前计算所有的查询操作,将部分操作保留在运行时计算,从而节省了时间开销。
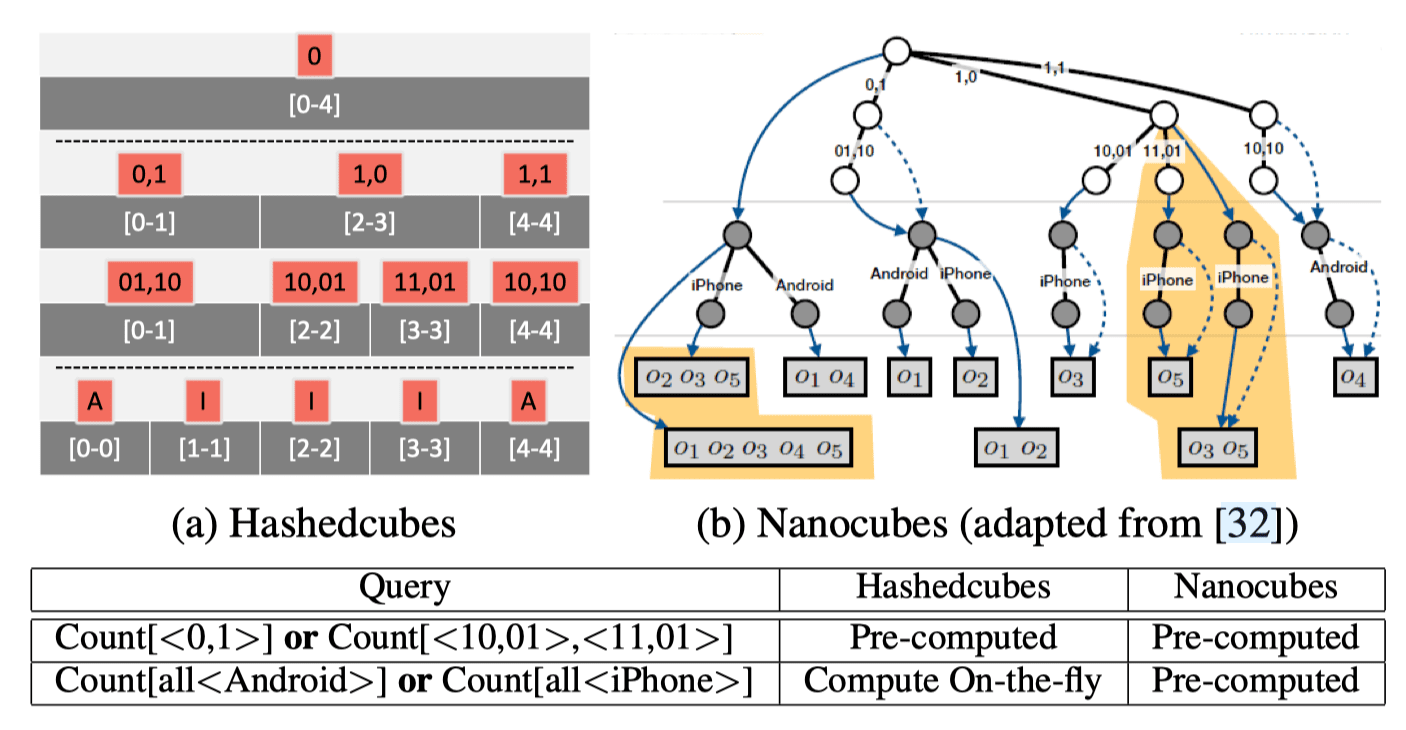
空间维度
空间维度的高效查询通常涉及到分层的空间数据结构,如四叉树。Hashedcubes 将四叉树中的四分之一作为一个 pivot,将该区域内的数据点排序聚合在一起,使得连续的数据点都包含在同一个分区内。
针对具有多个空间维度的情况,使用四叉树的不同层来交错划分空间区域,每个空间维度都拥有一个独立的四叉树,如下图中红蓝两色所示:
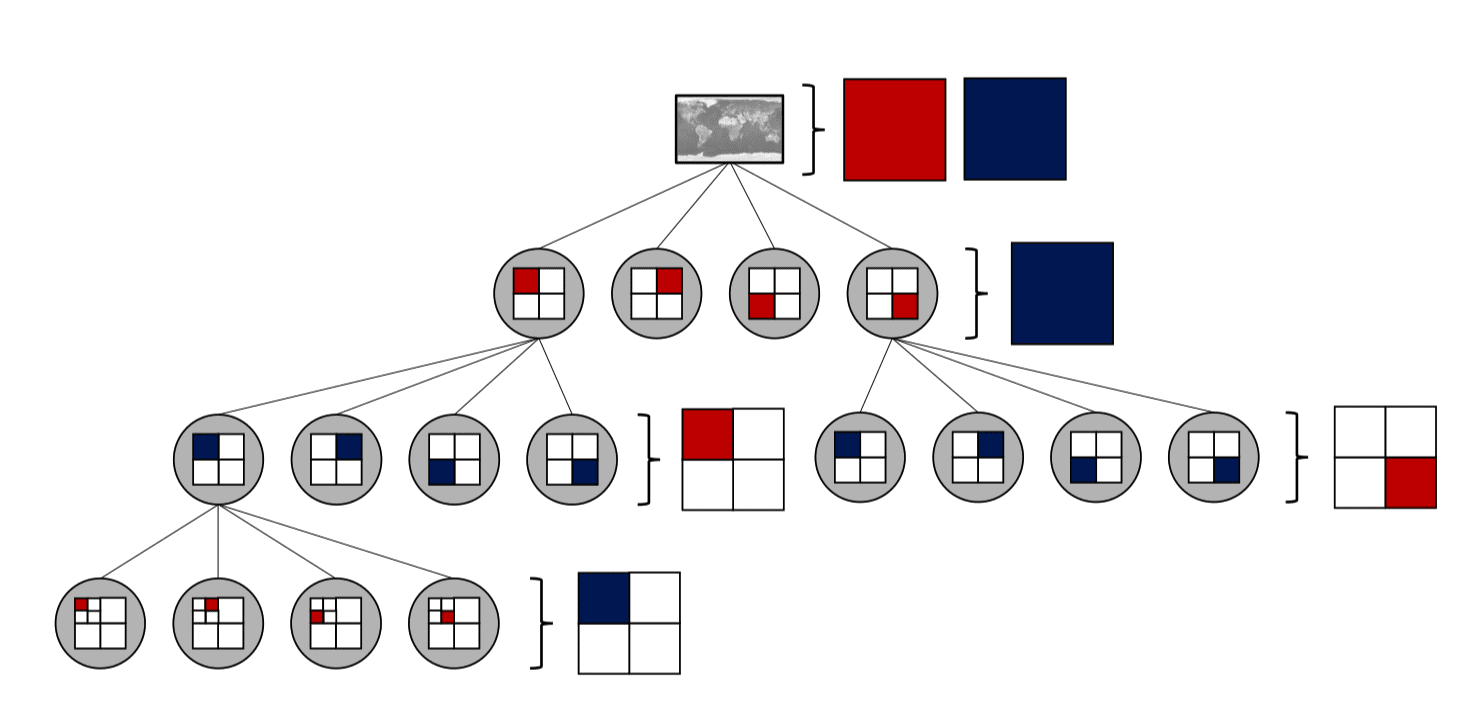
Hashedcubes 的构建需要控制最小叶节点的大小。每个维度的输出都是下一个维度的输入,用于进一步细分子维度的区域,所以需要控制最小叶节点的大小,太小则会导致子集过多,而太大又会影响可视化结构的精确性。这一大小同时也会导致性能表现和内存占用的大幅变动。
类别维度
对于不同的粒度,会产生不同大小的 pivot 数组。Hashedcubes 通过存储一个 CategoricalNode 的数据结构来基于独特属性的个数来产生稠密向量。如上图中的例子,系统会为大小为 4 的输入创建 4 个 CategoricalNode,每个 node 里会包含一个含有两个 pivot 的向量。对于含有多个类别维度的数据,Hashedcubes 会依次处理(而不是类似空间维度中交错处理的四叉树)。
时序维度
采用类似于类别维度的处理方式,以一段时间作为一个 pivot 的边界。如下图所示。使用两次二分查找来寻找到起止时间所在的 pivot 并对边界累加即可快速的到查询结果。
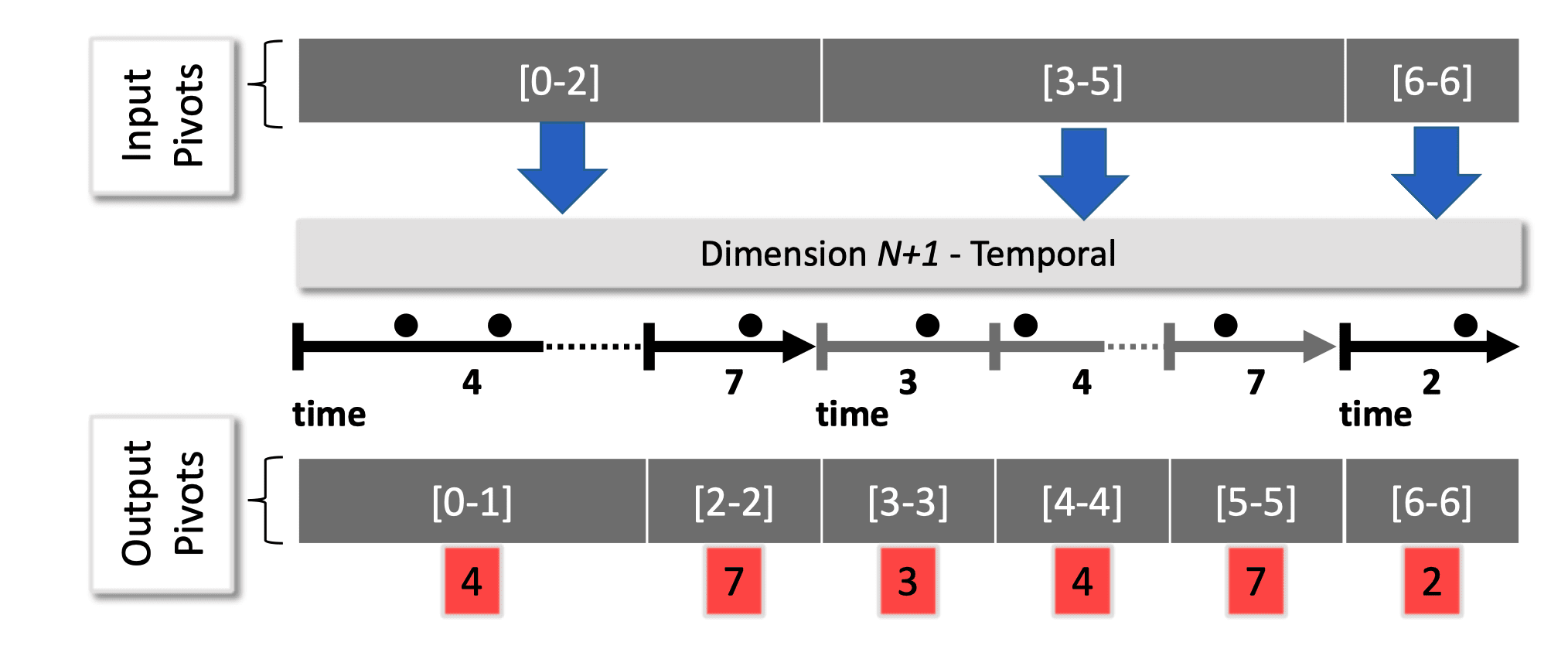
查询流程
Hashedcubes 的查询由一系列子句(clause)组成。每个子句包括一个维度,并定义是否有范围限制(constraints)或分组查询(group by)。查询的结果则包括一个经过聚合的 pivot 组成。最初的查询范围包括了整个数据集,即整个数组,每一维度的限制或分组所查询到的部分 pivot 用于下一步的搜索,类似于使用了两个列表的 BFS:一个用于拓展范围,一个用于临时存储。
由于查询都是在基于数组的数据结构上进行的,所以相对于于基于树的数据结构,可以更充分地利用 CPU cache 保证查询的高效性。
实现
服务端采用 C++ 编写,数据来源为 csv 格式的结构数据。客户端基于 Web 构建,采用 OpenStreetMap 作为地图提供商。客户端与服务端之前通过 HTTP API 沟通。
数据集与评测
本文涉及的数据集包括:
- 基于位置的社交网络:Brightkite 与 Gowalla
- 航线准时性数据:过去 20 年的美国航线准时性数据,采用了 3 种不同的 schema,其中包括一种和 Nanocubes 相同的 Schema,一种和 imMens 相同的 Schema
- SPLOM:一个合成的测试数据集,具备不同的 bin size,用于在 ScatterPlot Matrix Benchmark 中测试 data cube 的性能
- Twitter:从 Twitter API 收集的一整年的推特数据,包括地理位置、设备和发帖时间、用户语言等维度
- 出租车数据:纽约不同公司出租车的接客点、下客点、时间等,包含两个 Schema 等维度
为上述各个数据集构建 Hashedcubes 所需要的内存、时间与最终生成的 pivot 数量如下表所示:

内存占用
Hashedcubes 相比 Nanocubes 大幅减少了内存占用,至多 降低了 5.2 倍。Nanocubes 使用 46.4 GB 内存的数据集在 Hashedcubes 中只需要 9.4 GB,远低于当下常见服务器的内存配置。
在实验数据集 SPLOM 上,Hashedcubes 的内存占用同样表现良好。其中,对于出租车数据集,Nanocubes 需要占用多达 321 GB 内存(估计),故无法完成任务。
构建时间
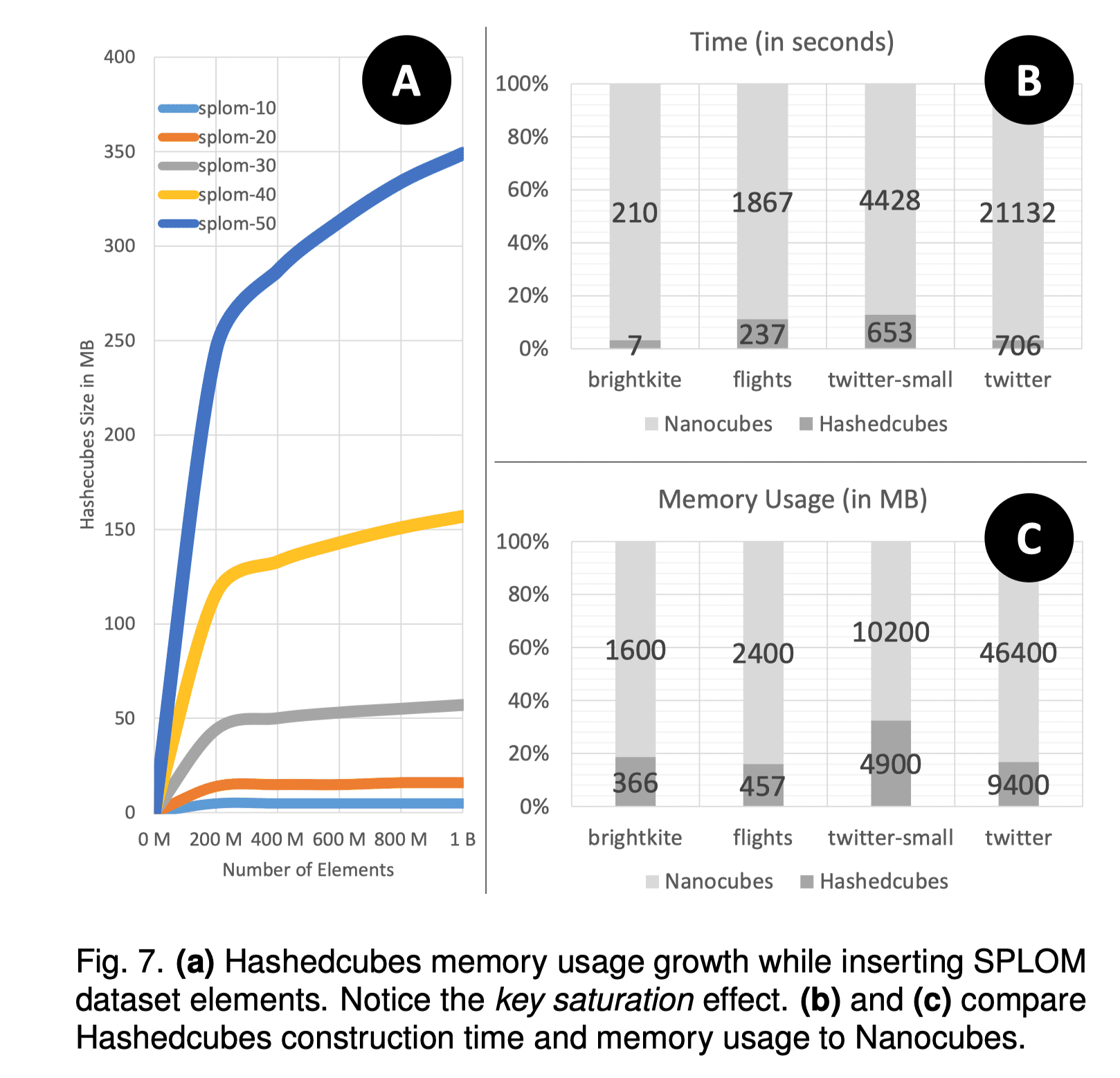
构建时间的主要瓶颈为排序过程的用时,尤其是在处理空间维度上的信息时(往往涉及到大量的排序操作)。经实验,和 Nanocubes 相比, Hashedcubes 的构建时间要快至多 30 倍,平均 10 倍。
查询延迟
实验所用到的查询取自 Nanocubes 的官网,包括一系列的刷选、连接操作等。下图为查询所耗费的时间实验结果,可以看到大多数查询的时间消耗都在 40ms 内,允许高于 25fps 的实时交互。服务端与客户端的沟通虽然也会消耗一定时间,但这部分时间主要由地图瓦片传输的时间决定,相对之下 Hashedcubes 所提供的信息传输时间可以忽略不计。
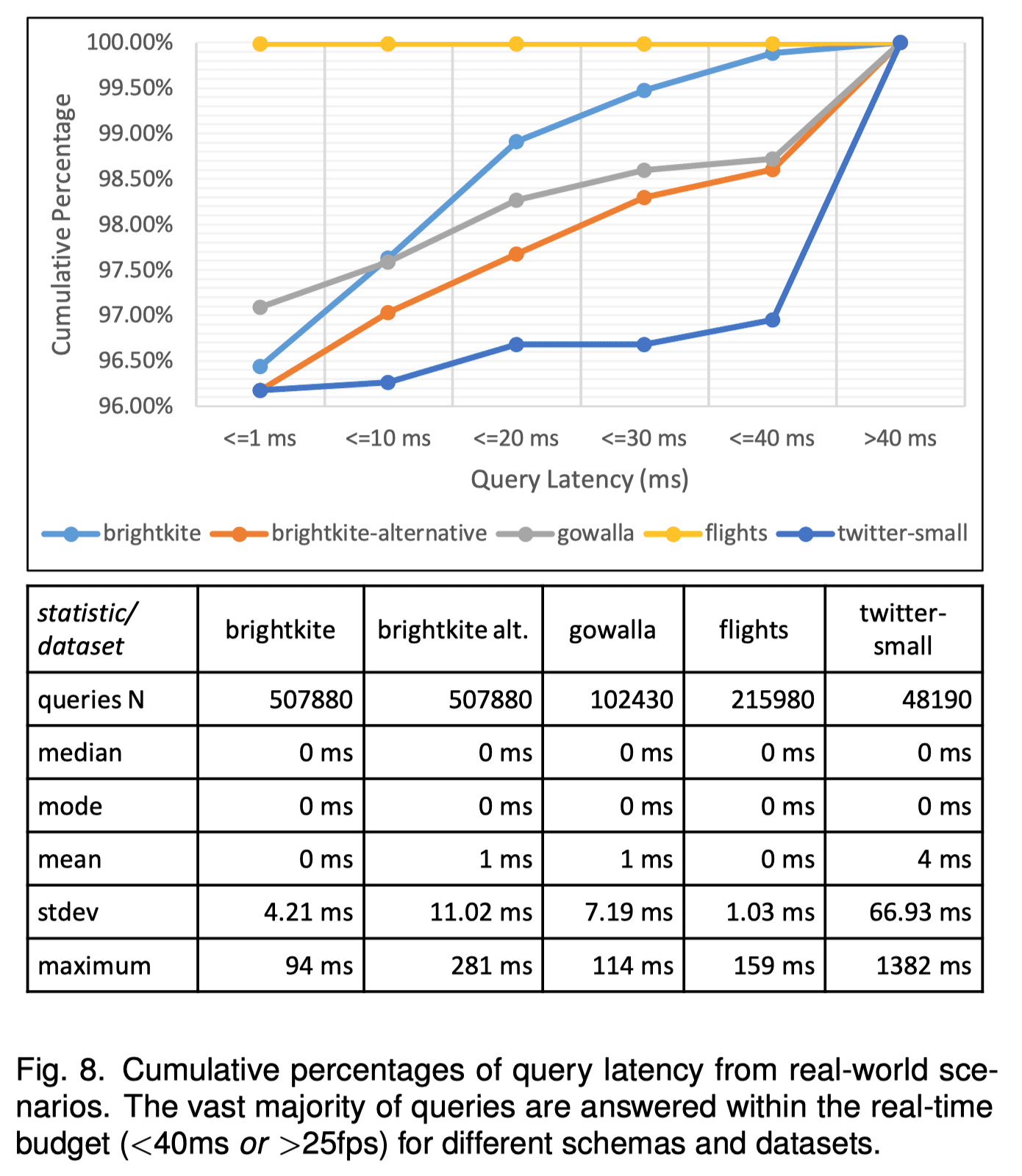
尽管在某些情况下 Hashedcubes 的查询时间略微慢于最佳效果(Nanocubes 的最差查询时间为 12 ms、imMens 平均查询时间为 20ms),但典型查询时间已经足够用于实时可视化互动系统的开发与实现。即便是在有上千万个元素的数据集的情况下,也只有约 2% 的查询时间超过了 40ms。
讨论
Pivot 构建的顺序
Hashedcubes 背后的核心方法为 Pivot Hierarchy。不同维度理论上可以按照任意顺序构建 pivot 数组,但经实际测试不同的顺序由于背后的排序开销不同,导致的构建时间和内存占用也会有许多不同(如对 Brightkite 使用空间 -> 时序 -> 类别的构建顺序,其最大查询时间从 94ms 增加到了 281ms,内存占用增加了 25% )。
与数据库的整合
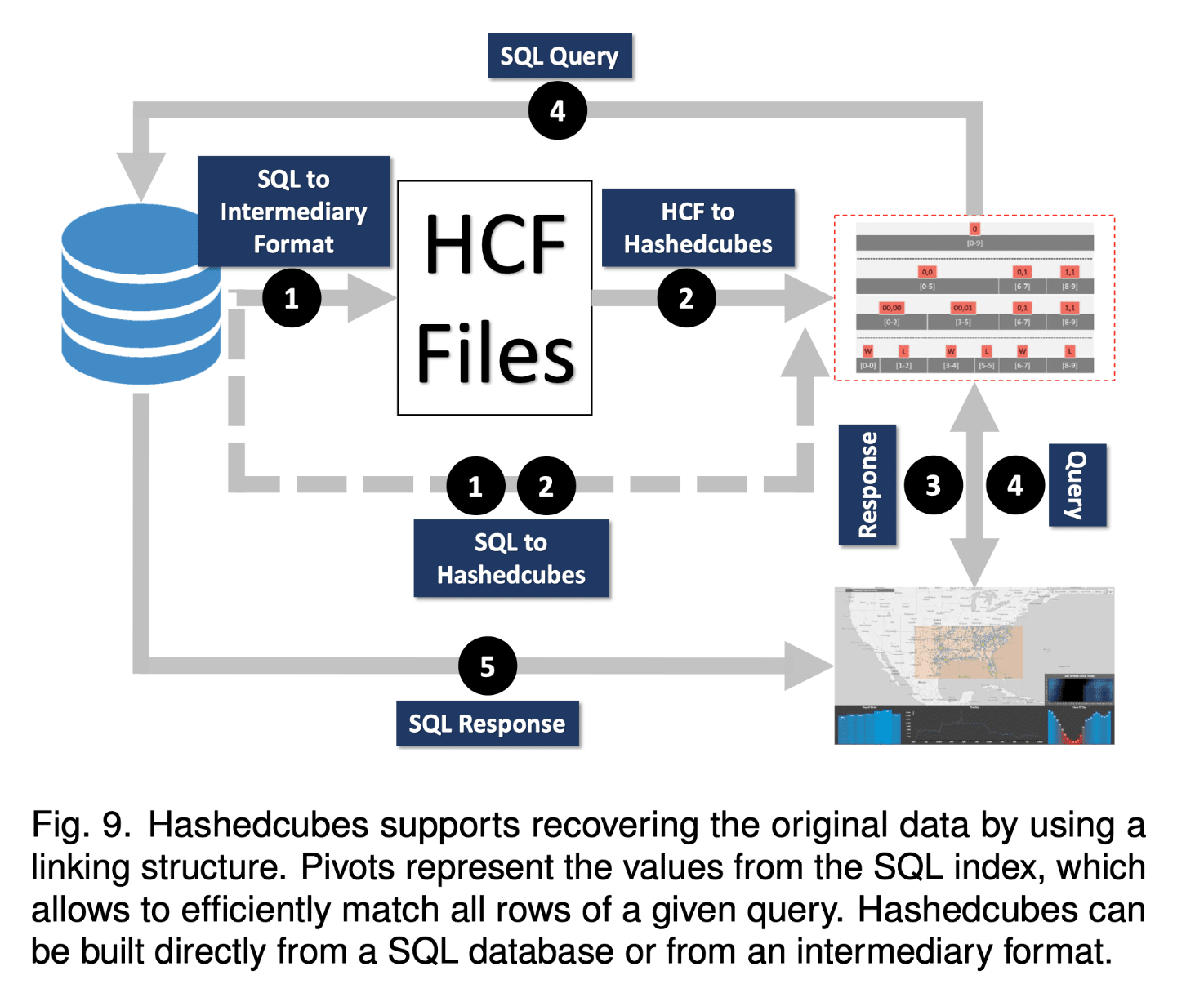
无论是 Hashedcubes 还是之前提出的 imMens、Nanocubes 都可以看做是近似数据库(approximate databases)。但 Hashedcubes 背后的简介概念使其和完整数据库记录的整合变得更加直观。通过将 Hashedcubes 内部的 pivot 和数据库的索引相关联,用户便可以直接从可视化结果中检索到原始数据,也可以让用户在视觉上的查询触发对应的 SQL 查询来同步检索完整数据。一个例子如下图所示:
叶节点大小与视觉准确性的 Trade-off
在 Hashedcubes 中,每一个维度的划分输出将作为下一个维度的划分输入。尤其是对于空间数据,最小的叶节点的大小即指定了单个空间最小划分区域的大小阈值。于是当一个空间区域内的数据个数达到阈值后,将不会再继续被划分。这些区域被称为 truncated pivot。这有利于高效查询、避免后续维度的划分过小,但在视觉上可能会引起异常(尤其是在数据集稀疏的地方)。
从该图中可以得到直观的对比。a 中,truncated pivot 用矩形来表示,b、c 中用圆形来表示聚合中心,可以看到不同 leaf-size 对最终渲染效果的影响:

未来工作
本文的未来工作主要在以下方面:
- 对维度计算顺序与各项参数的自动计算与优化。探索一个评价标准,使得系统在构建索引前自适应调整维度顺序、叶节点大小等参数;或创建更多的 Hashedcubes 实例来优化构建过程、最小化查询时间和内存占用。
- 动态数据或流数据的处理能力的探索。
- 对紧凑内存数组(Packed Memory Array or PMA)的进一步深入探索。对这一现有数列结构的良好利用这可能可以进一步优化效率。
[1] C. A. L. Pahins, S. A. Stephens, C. Scheidegger, and J. L. D. Comba, “Hashedcubes: Simple, Low Memory, Real-Time Visual Exploration of Big Data,” IEEE Trans. Visual. Comput. Graphics, vol. 23, no. 1, pp. 671–680, Jan. 2017, doi: 10.1109/TVCG.2016.2598624.
[2] L. Lins, J. T. Klosowski, and C. Scheidegger, “Nanocubes for Real-Time Exploration of Spatiotemporal Datasets,” IEEE Transactions on Visualization and Computer Graphics, vol. 19, no. 12, pp. 2456–2465, Dec. 2013, doi: 10.1109/TVCG.2013.179.
[3] Z. Liu, B. Jiang, and J. Heer, “imMens : Real-time Visual Querying of Big Data,” Computer Graphics Forum, vol. 32, no. 3pt4, pp. 421–430, Jun. 2013, doi: 10.1111/cgf.12129.
[4] C. A. de L. Pahins, cicerolp/hashedcubes. 2022. Accessed: Jun. 14, 2022. [Online]. Available: https://github.com/cicerolp/hashedcubes